BEYOND MENUS:
THE RATS-A-STRATZ OR THE BAHDEENS
(C) Paul Pangaro 1982. All Rights Reserved.
Harvard Computer Graphics Week
Harvard University
Graduate School of Design
1982
This paper was written and presented in 1982. It was the
first documentation of the system Do-What-Do {(c) 1979} which
I had conceived and developed in the few years before, and which
had been presented at seminars at MIT and elsewhere.
The text was written at a time when non-keyboard interaction
was achieved via "graph tablet and pen" rather than
mouse. All the concepts that allude to tablet touches and menu
action apply equally well to mouse clicking.
Conversion of the original paper from a printed copy was via
OCR, apologies for any artifacts remaining from that process.
ABSTRACT
As graphical interfaces gain favor over keyboard and text-driven
interaction, the search for techniques that are directly visual
continues in earnest. Menus are considered to be the best in
state-of-the-art computer interaction, but have been in use at
least since Sutherland's SKETCHPAD in 1963. This paper argues
that although present menu systems have some advantages for interaction,
especially for non-technical users, they are unnecessarily restrictive.
A research program funded by the Admiralty Marine Technology
Establishment, UK, and the US Army Research Institute applies
a theoretical framework to the problems of computer-based instruction
and computer-aided decision and design. Implications for a generalized
approach, applicable in any situation with persons interacting
with machines, have emerged and are reported in this paper.
The main breakthrough promised by the research program stems
from the formal application of Pask's Theory of Conversations
to person/machine dialogue. Useful definitions for transaction,
interaction, and conversation are developed in a framework of
knowledge representation. These concepts, and simple metrics
for the utility of an interface, are offered as well-defined
characterizations of person/machine interaction.
The claim for the resulting system is that, at worst, it is a
goal-directed system that is self-teaching and adaptive to the
user's learning style; at best, it is extensible, it can be personalized
easily, and actually aids in the design process in tangible ways.
The necessary relationship between frameworks to study human
communication and the advance of human/machine interaction is
argued.
PREFACE
The vocabulary of any individual or group is quite idiosyncratic.
The acquisition of this vocabulary by anyone outside the group
is often a haphazard process and is usually fraught with misunderstandings.
A cousin of mine had two expressions that were particularly difficult
for me to fathom when I was younger. They are "ratza-stratz"
and "bahdeens". The words cropped up in what seemed
like any context and they appeared to have the identical meaningt
but I hadn't a clue what the meaning was.
Finally I realized that they had no specific meaning;
they were synonyms for "whosis" and "whatchamacallit".
Part of their magic was the lack of apparent correspondence between
their meaning and their origins. Jargon invariably arises in
ways that are unpredictable and spontaneous.
One's identity is very much encapsulated in such inventions;
to communicate them to others is to express this identity. Without
such freedom, the "individual" does not exist.
Any use of computers must encounter these subtleties of communication
and individuality. From the perspectives of training (system
to user) and individualization (user to system), present interfaces
are incapable of communicating personalized meanings and capture
them only with great effort. For the individual to continue to
exist the present conditions must change.
INTRODUCTION
Advances in knowledge representation schemes have been used
in expert systems (Steels 1979) with mixed success, but have
not impacted user interaction directly. I believe that this has
been the case because until recently no theory of human communication
has provided a detailed set of procedures with which to characterize
intelligent dialogue, and that could be embodied in software
at the human/machine interface.
This paper presents the results of design work and software experiments
to be applied to the construction of expert advisor systems.
The concepts incorporated in software have been tested in a variety
of component forms, and the purpose of the near-term work is
to bring these components together in the construction of a unified
Intelligent Support System. The appropriate extensions to knowledge
representation schemes provide an environment which contain interactive
modes (such as menus) as a subset, while additionally providing
training and paired dialogue within a uniform system design.
MENUS
In 1963, Ivan Sutherland's SKETCHPAD contained all of the essential
elements of present day interactive, simulation-based graphics
systems. Menus were the mode of interaction. Since then, many
changes have occurred (for example, physical switches may be
replaced by virtual ones, Bolt 1977) and the speed and power
behind the interface is greater; but basically, the transactions
required of the user, and their semantic components, have not
changed.
Generically, a menu refers to a list of choices available at
a given moment in the user's interaction with the software system.
In that sense, command line systems (in which functions are invoked
by text commands with parameter arguments, for example, DRAW-LINE
0 0 10 10 RED) are functionally identical to menus. For those
who cannot' type, menus are better especially when displayed
on graphics devices with some mechanism for the user to "pick"
choices.
One advantage cited for menu displays is that the possible choices
are visible, and therefore do not need to be memorized. However,
for any system with a range of options, there are too many options
to be shown at one time. The usual solution is to break up the
entire repertoire into subsets, and to arrange these subsets
into a hierarchy. As was discovered at the Architecture Machine
Group in both the PAINT system and the Spatial Data Management
projects, this flipping about from level to level is wasteful
and tiresome. There is no purpose in spending many precious tablet-pen
motions and touches simply to traverse a fixed topology to get
to a place, especially after the place and its contents are known.
In nearly all menu systems, there is the implicit interpretation
of "place" to mean "the ability to input or modify
the state of specific parameters." Traveling to that place
in the tree means that the succeeding motions (if they are required,
and they nearly always are) refer to those specific parameters.
A classic example is "Line mode." After invoking this
function, the next two tablet touches are interpreted to mean
the endpoints of the line to draw. Unless there is the next transaction
is unusual (such as a touch to a special menu area for color,
or to change functions altogether to Circle or some such thing),
these two points must be given next.
Consider a further problem: here I am in sub-mode, sub a, sub
viii, and I want only to get to a different state within the
same mode; say, to widen my line and to change its color. Two
or perhaps four moves and touches of my tablet pen and I have
what I want. Now my touches place a fat blue line instead of
a thin red one. But, suppose that I want my next picture element
to be that thin red linet once again my only course is to reset
the earlier parameters. This means that 1) I must be able to
reconstruct them exactly, whether by eye or memorizing and resetting
their values numerically, and 2) I am now unable to return to
their newer values, namely, the fat blue line.
These difficulties may be rephrased. Firstly, I must travel geographically
in the fixed hierarchy of commands to give a particular interpretation
to the just-succeeding transactions. This is equivalent to setting
a "state" of the system. Secondly, any parameter settings
(which technically are encompassed in the "state of the
system") of those transactions are lost by further activity.
Moreover there is the additional burden of fixed hierarchies
t I am at the mercy of the programmer's choices as to how functions
are grouped.
INSTANCING AND GOALS
Each of these difficulties my be avoided by a simple re-interpretation
of "place" in the menu of functions. Instead of defining
each place to be equivalent to one "state" of the system,
consider it to be the ability to define an "instance"
of a function. Parameters of line width and color, for example,
would be set in the same way, and the succeeding actions on the
picture would reflect this new state of the system. But the system
retains this "state" and provides it as a "user-defined"
menu choice.
Hence, upon defining a "thin red line" instance, I
can reproduce it at any time from a single menu choice. Of course
the management and arrangement of such proliferating menus requires
careful design; it would in fact take more than a single action
to find and activate the appropriate button. A further elaboration
would make menu arrangements dynamic in themselves and sensitive
to context, but this area is not yet sufficiently explored.
In sophisticated systems, the new menu choice that results from
the defining actions might be given full graphical appearancet
a new menu button which is a picture rather than text, and determined
by the user. But even if left as a text string, the power derives
from the "configuring", or extensibility, of the system:
sequences of transactions are now coalesced to the single menu
choice and according to the user's goals.
Another entrance into the pre-defined system function of "Line
mode", and parameter setting to fat red lines produces another
menu choicet side by side with the thin blues. Single transactions
have the effect of many, with the precise repeatability that
is needed. There must of course be an additional mechanism whereby
undesirable instances are forgotten and desirable ones arranged.
Consider that a configuration of the system may be made by the
user and without the intervention of the programmer. One complexity
facing the uninitiated user of the usual menu system is the variation
between each choice in the system: some require further actions,
some do not; these actions are generally different in each case
and require strictly correct responses on the user's part. An
alternative would be the presentation of only a small set of
choices, each of which is consistent with its neighbors. For
example, a PAINT system which started with only four buttons,
each of which draws a line of different color and width, would
be relatively easy to teach. Once familiar, the user would still
have access to the full set and also be able to arrange them
according to design or to whim.
It is fair to say that coherent action involves goals, whether
well-specified or not, fixed or not. User transactions at an
interface involve goals, and certainly a "user-oriented"
system must be sensitive to this.
The action of "menu choice" may be best understood
as an attempt to complete a goal, or more likely, as one step
toward the completion of a goal. Goals operate at many levels
of abstraction and process. Decision and design have goals and
without goals one can neither decide nor design.
Yet, nearly all available menu systems totally ignore goal-directed
activity. This is part of the tradition in computer science which
places heavy emphasis on procedural descriptions (executable
code in sequential machines). This encourages application builders
to provide systems where the only possible transaction is to
execute a procedural descriptiontto hit a menu button, type a
command. Multiple-level structures in which goals interact with
procedures may be expressed in a few well-know systems (Hewitt
1972) but their straightforward application to user interface
and menu systems has been missed.
The "instancing" scheme described above is one simple
step toward such an improvement. The dynamic status of the function
(its parameter settings) is captured and instanced and made available;
insofar as this simple sequence is a goal or fragment of a goal,
the system has captured it for subsequent use. The management
and aggregation of experience by the interface as a focused activity
which converges on "the design" (rather than merely
proliferates previous and unwanted trials) is the topic of a
sequel paper.
LEARNING "THE" SYSTEM
Many of us have spent hours laboriously demonstrating and tutoring
new users in. the use of our software systems. We have pondered
over the problems of over-the-shoulder coaching, lengthy manuals
that are impossible to index, and the ubiquitous "help"
facility. "All you need to know is how to use the help command"
is a frequent but ridiculous excuse for programs that attempt
to explain themselves.
Given a need to arrange the repertoire of pre-defined functions
in a menu-driven system, it makes sense to have all tutoring
correspond to that hierarchy. Put another way, there are two
fundamental aspects of human/machine interaction: commands to
execute procedures ("do this") and descriptive transactions
("what does this do"); and they may flow in both directions
between user and machine. What is required at the interface is
a means to bring both these aspects into one-to-one (or many-to-one)
correspondence.
A formal calculus has been developed which makes this correspondence
(Pask 1979). Machine-based systems have been constructed for
education and training which rely on a knowledge representation
scheme called "entailment meshes" (Pask 1976, Pangaro
1981). This term is a good characterization of the structures
involved, in two ways.
First, the interconnections between topics (the "do-ables"
and "know-ables" of the domain) are not hierarchical;
they are a heterarchy, that is, there are no inherent "higher"
or "lower" entities. Hierarchies emerge out of the
mesh only during action and interrogation as a result of transactions
with a user.
Second, connections or relations between topics cannot not be
arbitrary and ubiquitous; they must follow the rule of entailment.
Consider the example:
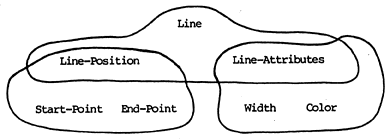
The surrounding boundaries indicate topics which "entail"
each other; that is, to understand/describe/communicate/construct
a given topic, all neighbors from at least one neighborhood are
required. The neighbors are a necessary and sufficient condition.
And there is more than one way to comprehend a given topic. Above,
for example, Line-Attributes may be derived/entailed/understood
in terms of Width and Color. Or, in a slightly different case,
Line Attributes may be understood in terms of Line-Position and
Line, which means that Line-Attributes are distinguishable in
the context of Line and Line-Position.
This example points up two aspects of the technique. First, the
apparent hierarchy is mis-leading because topics become "more
primitive" than others only as a result of dynamic interaction.
The level of a topic is a subjective view, and relative to a
desire for action or a desire to comprehend. Both kinds of goal
consider the relations between an entity and its context, where
context may have a variety of possible interpretations.
Second, there is a fundamental requirement that the entailment
mesh must contain entities which are distinct by virtue of their
relations with other entities. It is this structure of knowledge
which gives it sufficient consistency to remain stable and provide
mechanisms for phenomena such as "memory."
The complete knowledge representation calculus contains many
significant rules for manipulation, including analogy elicitation,
the automatic creation of generalizations and exemplars, and
the orderly increase in the number of relations before a point
of ambiguity or contradiction in structure. There are also conditions
under which further structure must be provided either by the
user or the system in order to resolve "confusion."
One primary advantage of the application of entailment meshes
to the machine interface is complete correspondence between the
command aspects of user interaction ("do this") and
the tutoring aspects ("what is this?"). This is evident
from the following sample series of transactions:
A user indicates "What-" "Line". (The following
description is independent of the question of how the
user indicates these particular topics beyond saying that they
are displayed on a screen and picked, as if from a menu.) The
system responds with a demonstration based on the two further
topics, Line-Position and Line-Attribute. For example, the following
text appears, accompanied by an appropriate motion graphic: "Line
is a function whereby Position and Attributes are indicated by
the user and a line is drawn on the screen." Helpful, but
not the entire story so far.
The user then indicates "What-" "Line-Attributes".
The system responds: "Lines have the attributes of Width
and Color." Seeing a palette at the screen bottom, the user
presumes that color is chosen directly; touching a shade of gray
in the palette causes in the appearance of the Color topic on
the menu screen to change; not because the topic is concerned
with Color but because the goal of Color has been achieved.
Continuing:
User: "What-" "Start-Point". System: "Use
the tablet pen to indicate the position for the line by first
touching at the Start-point, then at the End-point." The
user then wishes to perform this function, and indicates "Do-"
"Line-Position". The next two tablet touches are interpreted,
as the tutorial indicated, as the Start-Point and End-Point of
the Line. At this stage, both of the Points and the Line-Position
have been indicated by the user, and the appearance of each of
these menu choices has been changed by the system to indicate
they have been achieved as goals (or, more appropriately in this
context, sub-goals).
Nothing further happens at this time. In every Paint-type system
I have seen, these two transactions terminate the Line activity
by placing the Line into the picture. In the "Do-What-Do"
(copyright 1979) system, however, the requirement is for all
entailed topics to be specified before any other topics are "achieved."
Thus there are two basic ways in which goals are achieved: directly,
by "doing", if they are parameter settings; and indirectly,
by achieving all of the required sub-goals. In this case, Width
is the remaining requirement for the Line to be achieved.
User: "What-" "Width". System: "The
Width is set by two tablet touches, the second Offset from the
first by the desired Width of the Line to be drawn." In
this case there is mere detail needed to clarify an otherwise
obscure and terse sentence. Such clarification resides in consistent
fashion inside the knowledge representation, to be revealed upon
further questioning by the user, as in "What-" "Offset".
The system responds, again with a short animation as well as
text, by demonstrating that "After the first touch is made,
the tablet pen should be Offset, or moved aside on the tablet,
just the distance desired for the Width of the Line." The
user then indicates "Do-" "Width"; the next
two tablet touches are then interpreted as the Width parameter
for Line; the appearance of the word Width on the menu changes
to indicate that a valid setting has been achieved; and so
does Line since it is a goal which has been achieved. At
this stage also, the Line appears somewhere on the screen in
the indicated Position with the specified Attributes.
There are some subtleties in the methods of Do-What-Do. It is
important to have many ways in which to achieve a goal,
perhaps many alternate input methods and even user-defined methods
and further goals. Also, once the system is given a goal, it
actively seeks ways to achieve it. If Line-Position were also
contained in another boundary with Type-Start-Point and Random-Vector,
there would be more than one way to achieve Line-Position. Suppose
Line-Attributes were already set from previous interaction; and
Random-Vector is provided by the system, meaning that it is a
goal which is always achieved. After "DO-" "Line"
is indicated, the system is trying to achieve what is entailed
by Line by any available method; merely typing two integers on
the keyboard to be interpreted as x,y Start-Point would then
result in the appearance of the Line.
The essence of the Do-What-Do method is specifically as follows:
a) Order of specification of parameters is not pre-determined
and fixed; design may emerge from the user in any order.
b) A fully mixed-initiative on the users part, of "Do-"
and "What-", is allowed. The distinction between tutoring
and activating is blurred.
c) Because the system holds a history of transactions, as to
whatever topics have been tutored as well as successfully activated
(i.e. without error and perhaps repeatedly), it can tutor at
later moments in a way adapted to the users previous understanding,
and even based on the individual's conceptual style (Pask 1976,
Pangaro 1982).
d) The Do-What-Do system is not based on states; rather, it is
goal-oriented. This means that the interconnections represent
conditions which interact, and all requirements to achieve goals
are easily seen from the displayed structure.
Recalling 'the advantages of instancing as opposed to state menu
systems, note that a further result of the transactions in the
previous section is the appearance of a further topic in the
heterarchy of the user: the topic which represents the procedure
of "Line with specific parameter settings." A further
indication at this or a later time to "Do-" "that-there-instance-of-Line"
would reproduce the Line at the identical position with identical
attributes. If desired, the further system function "Do-What-Did"
could clear any specific parameter, say the Start-Point, by the
sequence "Do-What-Did" "Start-Point". Then
the sequence "Do-" "that-instance-of-Line"
and a tablet touch in whichever place would reproduce the Width,
Color and End-Point as before but would draw a new Line to the
new Start-Point. Reflection on the generality of this will reveal
a new meaning for extensible environments in the context of goal-directed
systems.
TRANSACTION AND INTERACTION
It has been disturbing to me for some time that popular terms
such as "user friendly" and "English language
interface" have been so long unchallenged for their imprecision
and inaccuracy. I will sketch some early trys at characterizing
with clear metrics what these vague terms are attempting to capture.
A "transaction" is defined to be the minimal actions
of the user to invoke a unitary procedure in a serial, digital
computer. The transaction is considered "complete"
when execution of the associated process is begun, whether or
not there are further transactions which the user may perceive
as continuous interaction.
The term "interaction" is reserved for a sequence of
transactions which achieves a goal or set of goals of the user.
The goal(s) need not, and often is (are) not, clearly known beforehand.
Note that the beginning and end of interaction is not clearly
defined, although, for specific and local goals, delimiters based
on transactions may be useful but not strictly appropriate.
"Conversation" is duly reserved for the formal development
in Pask (1975); the unified framework of objective and subjective
transactions provides a mechanical means for measuring that communication
at an interface has taken place. The strict interpretation of
the paradigm as described above for Do-What-Do in tutoring mode
is consistent with this formalism. The essence is that shared
understandings between the user and the system can be shown to
converge to stable concepts, both for the pre-existing system
operations (so-called "tutoring") and the goal structures
which are imbedded in the interface (so-called "individualization"
).
The proposal here is for a "metric of utility" based
on the above definitions. It is likely that the most fruitful
approach would involve the concept of self-organisation, and
such a measure is contemplated. For the present, a measure consistent
with information theory is proposed.
PROPOSED METRICS OF UTILITY AND INDIVIDUALIZATION
Imagine for simplicity a fixed set of choices on a menu. One
crude measure of the number of bits required (in the Shannon
sense) is simply the base-two logorithm of the number of choices.
Presume a menu in a graphically-based system in which there are
16 possible modes to choose from. "DO-" "draw"
is chosen by the user. Assume this requires 4 bits of distinction
(although a careful ponder on the question "How many bits
are required to express one point using a tablet pen in a 1024
x 1024 bit field?" reveals the real limitations of such
Information Theoretic measures.)
Suppose that this pick takes 1 transaction; a single tablet hit
on the menu button. Suppose further that this reveals the menu
choices of Line, Circle, Rectangle and Blotch modes; picking
Line mode is an additional 2 bits with 1 further transaction.
Let us say that to set the Line parameters of Start- and End-Points,
Width and Color requires an additional 5 transactions which specify
roughly 50 bits of data.
Let us therefore say that relative to this interface and the
indicated goal, the "Metric of Utility" is equal to
the number of specified bits divided by the number of transactions
required; in this case, the ratio of 56 to 7, or 8. This is a
crude measure of the overall utility of the system in achieving
the stated goal. Matters of processing time and ease of performing
the transactions are simple and difficult to quantify, respectively,
and are subordinate to the main point.
Here now is the essence of the matter: Assume that further Lines
of the same Width and Color are desired, but in different Positions.
It is therefore necessary to backtrack by indicating "Do-What-Did"
"Line Position" (4 bits in 2 transactions, say). New
Lines will appear when this instance is activated and 2 Points
chosen (38 bits in 3 transactions). The new Metric of Utility
is 4 + 38 to 2 + 3, or 8.4. On the next occasion when no further
backtracking is required, it is simply 38 to 3, or 12.6.
It is unfair to consider these later values independent of the
first; hence a further ratio is derived from the earlier figures,
dubbed the "Metric of Individualization", e.g., 8.4
to 8 = 1.05; 12.6 to 8.4 = 1.5.
When an interface has no memory whatever, this measure must remain
at unity. When there is memory, of which parameter memory and
extensibility are simple examples, the measure increases in value
as the system becomes "individualized." This is a rough
measure of the amplification achieved by the features of the
system.
I propose these measures in their primitive form to challenge
the development of appropriate and useful metrics, which are
an essential but missing component of interface research.
EXTENSIBILITY
Arguments for the power of extensible systems are well established;
an argument-by-example was constructed in the context of animation
environments (Pangaro, Steinberg, Davis and McCann, 1977). It
is occasionally noted that the added complexity of training in
the use of extensible systems may be too great for naive users.
The implication of the metrics suggested above is that without
extensibility, the utility of a given system is of constant value,
that is, it does not increase with usage. The person may become
more accustomed to "thinking along the lines of" the
provided functions and hopefully will become "faster"
at using the system. However, without extensibility the system
cannot be tailored to individual needs.
Extensibility which does not account for goal-directed activity
on many levels of discourse does not allow true extension of
the individual into that medium. If I now say to you that the
whatsis is missing from the framls because you can't imbed the
kinesis, then you will understand me in the context of this paper.
Until the whosis goes inside the whatzit the me-go is too slow.
SUMMARY
The following positive results are obtained by application of
concepts described in this paper and characterized by "Do-What-Do":
a) A new power in interface design is revealed by the application
of practical approaches to human communication: the incorporation
of goals into the interface rather than at it can redefine the
meaning behind extensible systems.
b) There can be unity in the self-tutoring aspects of the system
(normally only fudged by "help" commands); hence the
User can ask the system "what is this function" in
the same vocabulary as "do this function", the vocabulary
here contained in the underlying knowledge representation.
c) The system can track performance history to know how best
to present tutorial material based on the known shared vocabulary
of user and system.
d) The system, to be both efficient and responsive to individual
users, must be capable of incorporating new definitions. When
coupled to capabilities for instancing, the ability to define
goal structures, and dynamic seeking to achieve goals, a new
meaning for individualization in interaction and interface design
is achieved.
BIBLIOGRAPHY
Bolt, R.A. Touch Sensitive Displays, DARPA Report, MIT Architecture
Machine Group, March 1977.
Bolt, R.A. Spatial Data-Management, DARPA Report, MIT Architecture
Machine Group, March 1'979.
Hewitt, C. "Description and theoretical analysis (using
schemata) of PLANNER", Report No TR-258, A.I. Laboratory,
MIT, 1972
Pangaro, Steinberg, Davis and McCann. "EOM: A Graphically-
Scripted, Simulation-Based Animation System", Architecture
Machine Group, MIT, 1977.
Pangaro, P. "CA S T E: Course Assembly System and Tutorial
Environment/A Short History and Description", System Research
Limited, Richmond, Surrey, UK, 1981.
Pangaro, P. "Overview of the CASTE 'AU' System and User
Documentation", System Research Limited, Richmond, Surrey,
UK 1982.
Pask, G. Introduction to Chapter 1, "Aspects of Machine
Intelligence", Soft Architecture Machines, by Nicholas Negroponte,
MIT Press, 1975.
Pask, G. Conversation Theory, Applications In Education and ..Epistemology,
Elsevier, Amsterdam, 1976.
Pask, G. "A Proto-Language", System Research Limited,
Richmond, Surrey, UK, 1979.
Pask, G. and Pangaro, P. Entailment Meshes as Representations
of Knowledge and Learning, Conference in Computers in Education,
Cardiff, Wales, 1980.
Steels, L. "Procedural Attachment", A.I. Memo 543,
A.I. Laboratory, MIT, August 1979.
Sutherland, I. "SKETCHPAD- A Man-Machine Graphical Communication
System", AFIPS Conference Proceedings, Spring Joint Computer
Conference, 23, 347-353, '1963.
-end-
© Copyright Paul Pangaro 1994 - 2000. All Rights Reserved.